Cursor Origin: Git Hosting Rebuilt for AI Agents
Cursor launched Origin, a Git forge built for AI agents: S3-backed storage, 22 commits a second, and auto-resolved merge conflicts. What it means for devs.
Git was designed for people. You write for an hour, push, open a pull request, and someone reviews it over coffee the next morning. Cursor just bet that this assumption is about to snap, and built a git host for the version where the reviewer is a hundred agents pushing code by the second.
At its first Compile conference on June 16, Cursor unveiled Origin, which it calls "a git forge for the agentic era." The waitlist is open, it ships this fall, and it is pointed straight at GitHub.
What Origin actually is
Origin is a place to store, review, and collaborate on code. Same job as GitHub or GitLab. The difference is the pitch about who it serves: AI agents as the primary user, not a feature bolted onto a workflow designed for humans.
It is Git-compatible, so your git push, your CI scripts, and your local tooling keep working without changes. The engine underneath comes from Graphite, the code-review startup Cursor bought in 2025, known for stacked pull requests and fast review at scale. Graphite co-founder Tomas Reimers ran the demo.
There is no pricing yet and no general-availability date past "this fall." Today it is a waitlist at cursor.com/origin and a very confident keynote. Worth keeping that in mind for everything below: most of these claims are a vendor describing its own unreleased product.
Why build a new git host at all
Fair question. GitHub works. Why reinvent the forge?
Because the load changed. Traditional git hosting assumes a human cadence: code written over hours, reviewed over days, a handful of pushes per branch per day. That shaped every design decision underneath it.
Now point a swarm of coding agents at one repo. Dozens or hundreds of them can clone, branch, commit, and rebase the same codebase at the same time, in seconds. That is a different traffic shape, and Cursor's argument is that the old infrastructure was never built to absorb it.
That fan-out is the whole thesis. If you believe most code in 2027 gets written by agents working in parallel, the bottleneck stops being the model and starts being the thing that has to serve a thousand simultaneous clones of the same branch. This follows directly from the shift where agents became the default way teams ship: once you have a team of agents instead of one, they all hit version control at once.
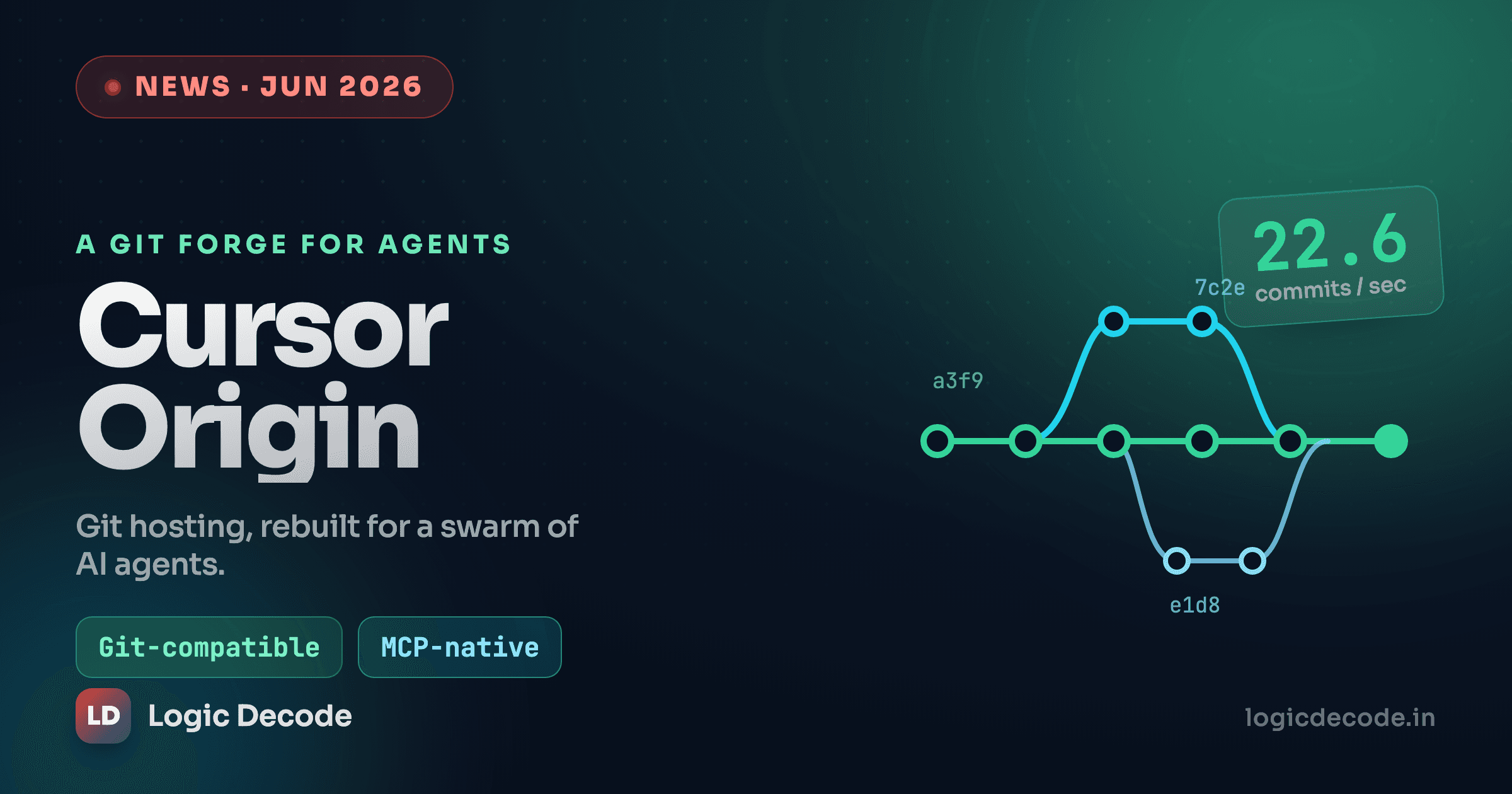
The numbers Cursor put on screen
The demo leaned hard on throughput. Here is what it showed:
| Operation | What Cursor demoed |
|---|---|
| Commits | 22.6 per second to a single repo |
| Clones | around 296,000 per hour |
| Pushes | around 81,000 per hour |
| Global sync latency | under 400 ms |
| Failover | about 10 ms, automatic |
Read these as a staged benchmark on a repo built to show them off, not a promise about your monorepo on a bad day. They are still a useful signal of what Origin is optimizing for. GitHub does not advertise "commits per second" because nobody was asking a human team to commit 22 times a second. Origin is built on the premise that something soon will.
How it scales
The architecture is the interesting engineering. Instead of git living on a disk attached to a server, Origin uses S3 object storage as the source of truth, with NVMe-based git fileservers sitting in front for speed, and what Cursor calls "infinite replicas" fanned out for worldwide sync and fast automatic failover.
The payoff of putting S3 underneath is that durability and scale become someone else's solved problem, and you can spin up read replicas close to wherever an agent happens to be running. The 10 ms failover number comes from the same idea: if a fileserver dies, another replica is already warm. Whether it holds up under a real, messy, multi-gigabyte repo is exactly the thing a demo can't tell you.
The genuinely new part: agents can drive it
Speed is the headline, but the design choice that actually matters is the interface. Origin exposes an API and an MCP server, so an agent can operate the forge directly: open a pull request, read review state, resolve a conflict, retry a failed build. It also ships built-in resolution that an agent can trigger when a merge conflict or a CI failure shows up, instead of waiting for a person to untangle it.
What is MCP doing here?
MCP (Model Context Protocol) is a standard way for an AI model to call out to tools and services. When Origin ships an MCP server, an agent doesn't have to scrape a web UI or guess at an API. It gets a structured, machine-readable way to ask "what's blocking this PR?" and act on the answer. That is the real bet: review and merge state become something a machine reads and edits, not just something a human clicks through.
This is where the Graphite roots show. Stacked pull requests, where one change builds on another in a reviewable chain, map neatly onto how agents work: small, sequential, dependent diffs. A forge that treats a stack of changes as a first-class object fits an agent better than the one-giant-branch model most of us rebase and merge by hand today.
The catch
Here is the part the keynote skipped.
Someone still has to review 22.6 commits a second. Agents made writing code cheap and did nothing to make reading it cheap. A forge that can absorb that write volume just moves the pile-up downstream to whoever signs off. "Origin auto-resolves the conflict" is reassuring right up until you ask who checks that the resolution was correct, and the honest answer is another agent.
Then there is lock-in. Origin is most valuable when it is paired with Cursor's own agents, and Cursor is no longer an independent company. It is now owned by xAI through SpaceX's $60B acquisition. A git host is the most sensitive piece of infrastructure a company runs, and "store all your source code with the AI lab that also wants training data" is a sentence your security team will want to finish reading before you click the button. Cursor has not published security or data-handling terms for Origin yet.
Git-compatible is your escape hatch
The best thing about Origin being plain Git underneath is that you can leave. If the pricing, the data terms, or the ownership ever turn sour, git clone and git push to a different remote is your exit. Keep that property. The moment a host adds a proprietary feature your workflow can't live without, the escape hatch quietly welds shut.
Quick check
What's the core problem Origin claims to solve that GitHub wasn't built for?
What I'd actually do
Nothing this week, because there is nothing to use yet. But Origin is worth tracking, and not for the reason the keynote wants.
The throughput numbers are a demo. The interesting bet is the MCP-and-API surface that lets agents operate the forge directly. If that works well, it is a real answer to a real problem, since git hosts genuinely were not designed for a swarm of agents to share one repo. If it mostly means "merge fast, review later," it is a way to ship subtle bugs at 22 commits a second.
So watch two things. First, whether agent-driven review and conflict resolution actually catch mistakes or just rubber-stamp them. Second, what the data terms say when they finally appear. Until then, keep your repos portable. It is plain Git, which means the control stays with you, and that is the right place for it to sit no matter who is hosting your code this year. If your branching and review habits are shaky, the Git and GitHub series is the place to firm them up before you hand the keys to an agent.

Written by
Rhythm Bhiwani
Engineer and relentless builder, happiest reverse-engineering hard problems until they click.
Enjoyed this?
Tap the heart to leave some love.
Be the first to react
Comments
Join the conversation.
Loading comments…


